基于ConceptNet的信息检索查询扩展方法
基于conceptnet的信息检索查询扩展方法
技术领域
1.本发明涉及信息检索方法技术领域,特别涉及基于conceptnet的信息检索查询扩展方法。
背景技术:
2.相关反馈的主要过程是:当用户要查询一项内容时,一开始,用户并不知道要输入的查询是否能找到相关的结果。但是用户很容易判断给出的结果是否是相关的。相关反馈在用户不断提交反馈结果的过程中系统基于用户的反馈优化查询的表示。然后,利用新的查询进行检索,直到得到用户满意的结果。相关反馈的过程可能需要用户执行多次反馈,根据用户的反馈反复优化查询。虽然相关反馈方法可以显著提升检索效果,但是对于大多数用户,他们可能不希望系统收集自己的信息。伪相关反馈方法将以上用户干预的过程自动化。伪相关假设从初始检索结果的排名前n篇文档与查询是相关的,这些文档称为反馈文档或者伪相关文档。然后从反馈文档中提取扩展项设计查询扩展方法,来重新定义原始查询的表示。随后进行第二轮检索。大量的研究已经证明伪相关反馈方法通过自动查询扩展可以有效提高检索结果。
3.现有技术中,伪相关反馈模型大多从频率、共现频率和接近度等方面选取扩展项,这种方式认为与查询距离近并且反复共同出现的词项可能与查询的语义是一致的。但是这些方法都是从间接获得可能与查询相关的扩展词项,并未直接衡量与查询表达类似的含义的词项。大量研究发现如果查询相关知识可以作为扩展词项集合的来源之一,有助于解决查询和文档中词项不匹配问题。查询扩展的主要思想是,扩展的查询可以更好地描述用户需求并避免由多义词引起的语义歧义问题。如果选择错误的扩展词项,扩展后的查询可能会偏离原始查询的语义,最终导致检索结果的准确率的降低。通过测量扩展词项与查询之间的语义关系来过滤查询词项有助于解决语义偏差的问题进而提高检索结果的正确率这些方法不能度量查询和扩展词项的语义相关性。这些伪相关反馈方法都是从反馈文档中选择扩展词项。该方法有一个显而易见的缺点:如果几个标注为相关的文档实际上是不相关时,该方法会在查询扩展程的第一步引入误差,并将导致查询扩展的过程可能产生与查询不相关的扩展词项。
4.例如,一种在中国专利文献上公开的“融合伪相关反馈与检索技术的自动图像标注方法”,其公告号:cn101075263a,其申请日:2007年06月28日,该发明提高了检索性能及标注的准确性,极大地改善了标注的可伸缩性,但是存在检索结果的平均正确率较低的问题。
技术实现要素:
5.针对现有技术检索结果的平均正确率较低的不足,本发明提出了基于conceptnet的信息检索查询扩展方法,能优化查询扩展以提高检索结果的平均正确率。
6.以下是本发明的技术方案,基于conceptnet的信息检索查询扩展方法,包括以下
步骤:
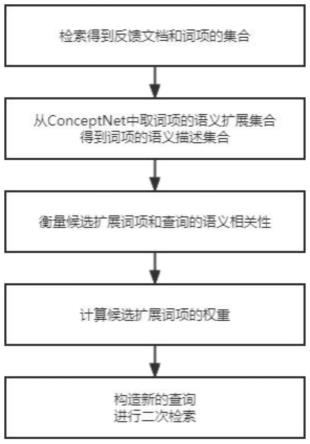
7.s1:使用bm25进行检索,得到反馈文档和词项的集合e;
8.s2:从conceptnet中取词项的语义扩展集合d,得到词项的语义描述集合c;
9.s3:衡量候选扩展词项和查询的语义相关性;
10.s4:计算所述候选扩展词项的权重;
11.s5:构造新的查询,并进行二次检索。
12.本方案中,从conceptnet知识库中获得的查询语义描述集合与反馈文档中获得的词项集合的协同过滤方法初步挑选候选扩展词项,有助于减少由于反馈文档选择的错误造成的查询扩展的误差,提出一种直接衡量查询与词项间的语义相关度的方法,联合词项间语义匹配与相关性匹配选择扩展词项,进行第二轮检索,在统计上与查询相关,确保词项在文档集合中的重要性;在语义上与查询相关,确保与查询的主题是一致的。有利于找到更好的扩展词项补充查询的语义,提高最终的检索结果的正确率。
13.作为优选,步骤s1中,文档的得分计算算式如下:
[0014][0015][0016][0017]
上式中,score(q,d)为文档得分,tf为文档长度的正则化表示,avdl为文档的平均长度,k1和k3为常数,qtf为查询词项q的频率,b为调节因子,dl为文档长度,n
′
为索引中所有文档的数量,df
t
为在所有文档中包含词项t的文档篇数,idf(t)为t在反馈文档中的重要程度。
[0018]
本方案中,对所有文档的文档得分进行排序,便于筛选目标文档形成反馈文档,便于后续计算,提高最终的检索结果的正确率。
[0019]
作为优选,步骤s1中,集合e为文档得分最高的10篇文档中所有词项构成候选伪相关词项集合。
[0020]
本方案中,将目标文档的所有词项构成候选伪相关词项集合,便于形成语义扩展集合,提高最终的检索结果的正确率。
[0021]
作为优选,步骤s2中,取以查询词项为头结点或者尾结点的所有关系三元组,并将关系三元组的所有头尾结点构成集合d,集合c为集合d和集合e的交集。
[0022]
本方案中,集合d由关系三元组和查询词项相关的所有词项的集合构成,集合c为集合d和集合e的交集,从conceptnet知识库中获得的查询语义描述集合与反馈文档中获得的词项集合的协同过滤方法初步挑选候选扩展词项,有助于减少由于反馈文档选择的错误造成的查询扩展的误差,提高最终的检索结果的正确率。
[0023]
作为优选,步骤s3中,衡量候选扩展词项和查询的语义相关性匹配得分计算算式如下:
[0024]
s(t,q)=sim(t,q)
×
idf(t);
[0025][0026]
上式中,s(t,q)为匹配得分,sim(t,q)为t和q之间的语义相似度,idf(t)为t在反馈文档中的重要程度,表示分别为以词项t为头结点和词项q为头结点的词向量,μ
t
为查询q中所有查询词与词t的语义相似度的均值,σ表示查询q中所有查询词与词项t语义相似度的方差。
[0027]
本方案中,直接度量查询与扩展词项间的语义相关度,通过衡量查询和扩展词项的词向量的相似度得到他们之间的语义相关度,联合词项间语义匹配与相关性匹配选择扩展词项,进行第二轮检索,可以识别出不具有高频率或共现频率的但可能语义相关的词项,提高最终的检索结果的正确率。
[0028]
作为优选,所述词向量的维度为300。
[0029]
作为优选,步骤s4中,所述候选扩展词项的权重计算算式如下:
[0030][0031]
λ∈{0,0.1,0.2,...,1.0};
[0032]
上式中,tf(t,d)为在文档d中,词项t的数量,n为反馈文档篇数,λ为平衡因子,w
t
候选扩展词项的权重。
[0033]
本方案中,扩展词权值计算方法同时考虑了词频(或词分布)和语义相关度它由两部分组成。第一部分代表候选词项的重要性,使用词项频率-逆文档频率或语言模型衡量。在统计上与查询相关,确保词项在文档集合中的重要性;在语义上与查询相关,确保与查询的主题是一致的,提高最终的检索结果的正确率。
[0034]
作为优选,对相关性匹配方法和词项间语义匹配方法的值进行归一化处理,平衡因子用于调整两部分的贡献,对候选扩展词项排序。
[0035]
本方案中,对相关性匹配方法和词项间语义匹配方法两部分的值进行min-max归一化处理,平衡因子λ用于调整两部分的贡献,并按照最终的值对候选扩展词项排序,提高最终的检索结果的正确率。
[0036]
作为优选,步骤s5中,新的查询计算算式如下:
[0037]q′
=(1-α)
×
q+α
×
q1;
[0038]
α∈{0,0.1,0.2,...,1.0};
[0039]
|tf|∈{10,20,30,50};
[0040]
上式中,α为平衡因子,q1为权重最大的前|tf|个扩展词项组成的向量,q为原始查询向量,q
′
为q1和q构成新的查询向量。
[0041]
本方案中,平衡因子α用于调整两部分的贡献,构建新的查询向量,新查询向量具有在统计上与查询相关,确保词项在文档集合中的重要性;在语义上与查询相关,确保与查询的主题是一致的特点,通过语义相关性匹配得分和候选扩展词项的权重,提高最终的检索结果的正确率。
[0042]
作为优选,使用新的查询向量进行二次检索,计算文档得分,按照文档得分的大小
排序并显示文档排序的结果。
[0043]
本方案中,使用新的查询向量提高检索结果的正确率,重新计算文档得分并排序,直观显示更优的搜索排序结果。
[0044]
本发明的有益效果是:能优化查询扩展以提高检索结果的平均正确率。
附图说明
[0045]
图1本发明基于conceptnet的信息检索查询扩展方法的流程图。
具体实施方式
[0046]
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
[0047]
实施例:如图1所示,基于conceptnet的信息检索查询扩展方法,包括以下步骤:
[0048]
步骤1:使用bm25(一种检索算法)进行第一轮检索,得到反馈文档和词项的集合e;
[0049]
步骤2:从conceptnet(一种语义网络知识库)中取词项的语义扩展集合d,得到词项的语义描述集合c;
[0050]
步骤3:衡量候选扩展词项和查询的语义相关性;
[0051]
步骤4:计算所有候选扩展词项的权重;
[0052]
步骤5:构造新的查询,并进行二次检索。
[0053]
步骤1中,使用bm25进行第一轮检索,得到反馈文档,得到反馈文档和词项的集合e,bm25模型是一种简单有效的检索方法。bm25根据所有数据集中查询词的重要性、文档的长度和词的频率等因素对文档进行排序,计算方法如下:
[0054][0055][0056][0057]
上式中,score(q,d)为文档得分,tf为文档长度的正则化表示,avdl为文档的平均长度,k1和k3为常数,qtf为查询词项q的频率,b为调节因子,dl为文档长度,n
′
为索引中所有文档的数量,df
t
为在所有文档中包含词项t的文档篇数,idf(t)为t在反馈文档中的重要程度。
[0058]
将所有文档的文档得分从高到低进行排序,得到排名前10篇文档,称为反馈文档或者伪相关文档。取这些反馈文档中的所有词项构成候选伪相关词项集合e。
[0059]
步骤2中,从conceptnet中取词项的语义扩展集合d,conceptnet以三元组的形式表达常识性知识的关系。例如,给定一个概念词项h,其在conceptnet中的三元关系表示为<h,relation,d>。取所有以h为头节点或尾节点的关系三元组。则与查询每个词项相关的所有词项的集合构成查询的语义扩展集合d。
[0060]
应用从conceptnet知识库中获得的查询语义扩展集合与反馈文档中获得的词项
集合的协同过滤方法初步挑选候选扩展词项,有助于减少由于反馈文档选择的错误造成的查询扩展的误差。在实际情况下,词项语义描述集中也可能存在一些与查询语义相关性不高的成员。如果查询词和候选词之间的语义相关度非常低,并且在反馈文档中没有出现,可以忽略。
[0061]
通过这种方式可以得到一个词项语义描述集合c={t1,t2,...,tn};
[0062]
其计算方式为:
[0063]
c=d∩e;
[0064]
上式中,d为过滤后的查询q的候选词项集,e为反馈文档中所有词项的集合。
[0065]
从conceptnet知识库中获得的查询语义描述集合与反馈文档中获得的词项集合的协同过滤方法初步挑选候选扩展词项,有助于减少由于反馈文档选择的错误造成的查询扩展的误差。
[0066]
步骤3中,衡量候选扩展词项和查询的语义相关性,伪相关反馈模型仅考虑词项的频率、逆文档频率等信息,缺少对词项间语义的衡量。衡量候选词项和查询词项的语义匹配得分s(t,q),计算算式如下:
[0067]
s(t,q)=sim(t,q)
×
idf(t);
[0068]
上式中,s(t,q)为匹配得分,sim(t,q)为t和q之间的语义相似度,idf(t)为t在反馈文档中的重要程度。
[0069][0070]
上式中,表示分别为以词项t为头结点和词项q为头结点的词向量,μ
t
为查询q中所有查询词与词t的语义相似度的均值,σ表示查询q中所有查询词与词项t语义相似度的方差。
[0071]
使用transe(一种算法)模型获得300维的词向量。
[0072]
步骤4中,根据联合相关性匹配和词项间语义匹配,得到所有候选扩展词项的权重,候选扩展词项的权重w
t
,计算算式如下:
[0073][0074]
λ∈{0,0.1,0.2,...,1.0};
[0075]
上式中,tf(t,d)为在文档d中,词项t的数量,n为反馈文档篇数,λ为平衡因子,w
t
候选扩展词项的权重。
[0076]
扩展词权值计算方法同时考虑了词频(或词分布)和语义相关度它由两部分组成。第一部分代表候选词项的重要性,使用词项频率-逆文档频率或语言模型衡量。对相关性匹配方法和词项间语义匹配方法两部分的值进行min-max归一化处理,平衡因子λ用于调整两部分的贡献,并按照最终的值对候选扩展词项排序。
[0077]
直接衡量查询与词项间的语义相关度,联合词项间语义匹配与相关性匹配选择扩展词项,进行第二轮检索。所提出的方法可以识别出不具有高频率或共现频率的但可能语义相关的词项。
[0078]
步骤5中,构造新的查询,并进行二次检索,根据步骤4中计算得到所有候选扩展词
项的权重,按照由大至小的顺序排序,选择权重最大的前|tf|个扩展词项,组成向量q1,与原始查询向量q构成新的查询向量q
′
:
[0079]q′
=(1-α)
×
q+α
×
q1;
[0080]
α∈{0,0.1,0.2,...,1.0};
[0081]
|tf|∈{10,20,30,50};
[0082]
上式中,α为平衡因子,q1为权重最大的前|tf|个扩展词项组成的向量,q为原始查询向量,q
′
为q1和q构成新的查询向量。平衡因子α用于调整两部分的贡献。
[0083]
使用新的查询向量q
′
进行二次检索,计算文档得分score(q,d),按照文档得分的大小排序,将排序的结果呈现给用户。
[0084]
同时考虑了词项间的语义相似度和词项的重要性两方面的贡献选择扩展词项,能够克服传统的伪相关反馈模型仅考虑词项的频率、逆文档频率等信息,缺少对词项间语义的衡量的问题。也能够克服传统伪相关方法的查询扩展受首轮检索方法的影响。直接度量查询与扩展词项间的语义相关度,通过衡量查询和扩展词项的词向量的相似度得到他们之间的语义相关度。在统计上与查询相关,确保词项在文档集合中的重要性;在语义上与查询相关,确保与查询的主题是一致的。有利于找到更好的扩展词项补充查询的语义,提高最终的检索结果的正确率。
完整全部详细技术资料下载
当前第1页 1 2
相关技术
- 供应链异常处理方法、装置、设...
- 应用程序管理方法及相关装置与...
- 一种基于深度学习的染色体结构...
- 用于管理机器学习系统的方法、...
- 基于Transformer和...
- 一种可调节遮光效果的计算机显...
- 基于计算模块的侧边扩展计算机...
- 一种基于图像特征对比和区块链...
- 石化生产过程的一种异变趋势预...
- 工程量清单持续存储和查询方法...
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1