





-
微信咨询

- 电话咨询 023-62619743 023-81361879
- 留言咨询
小当家ISV
互联网高新技术服务商
全球共有10多个国家和地区1000多个平台,20万+商户使用
用户登录
全球共有10多个国家和地区1000多个平台,20万+商户使用












扫码加微信免费试用

源码交付 免费技术支持






三级分销丨社区团购丨上门服务丨打车代驾丨医疗问诊

点餐收银丨CRM丨ERP丨酒店丨生产管理丨批发零售系统

短视频丨聊天交友丨外卖跑腿丨租户管理丨在线票务

蓝牙控制丨空调控制丨血压检测丨共享设备丨人脸识别

三级分销丨积分系统丨级差佣金丨直销模式丨合伙人分红

直播系统丨短视频APP丨电商直播丨礼物系统丨社交类

慢SQL优化的常用方法
(1)建立物化视图或尽可能减少多表查询。(2)以不相干子查询替代相干子查询。(3)只检索需要的列。(4)用带in的条件子句等价替换or子句。(5)经常提交commit,以尽早释放锁。(6)避免嵌套的游标(Cursor)和多重循环等。(7)在经常查询的列上创建索引,提高查询效率。(8)避免使用模糊查询进行匹配,如果一定要使用,建议使用最左模糊匹配原则。(9)慢的查询的sql,根据性能和存储容量大小进行评估,适当的可以考虑水平分表和垂直分表,以提高sql的查询性能。(10)查询数据是否存在,适当的可以使用exists替代in。建表1.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连 接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。2.尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间, 其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。临时表避免频繁创建和删除临时表,以减少系统表资源的消耗尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table,然后 drop table,这样可以避免系统表的较长时间锁定。游标的问题尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。游标的一个常见用途就是保存查询结果,以便以后使用。游标的结果集是由SELECT语句产生,如果处理过程需要重复使用一个记录集,那么创建一次游标而重复使用若干次,比重复查询数据库要快的多。使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。事务尽量避免大事务操作,提高系统并发能力。数据量问题13.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。具体SQL优化 1.避免使用select *select *不走覆盖索引,会有大量的回表操作,从而导致查询SQL的性能很低。应该使用具体的字段代替*,只返回使用到的字段。 2.用union all代替unionunion可以获取排除重复后的数据,union all可以获取所有数据,包含重复的数据,排除重复的过程需要遍历,排序和比较,他更耗时,更消耗CPU资源,所以如果能用union all,尽量不用union,除非是业务场景中不允许产生重复数据3.小表驱动大表in 和 not in 也要慎用,否则会导致全表扫描。对于连续的数值,能用 between 就不要用 in,对于子查询,可以用exists代替。用小表的数据集驱动大表的数据集in关键字,他会优先执行in里面的子查询语句,然后在执行in外面的语句,in里面的数据量很少,作为条件查询速度更快exists关键字,他会优先执行exists左边的语句(即主查询语句),然后把它作为条件,去跟右边的语句匹配,如果匹配上,则可以查出数据,如果匹配不上,数据就被过滤掉了in适用于左边大表,右边小表exists适用于左边小表,右边大表4.批量操作每次远程请求数据库,是会消耗一定性能的提供一个批量插入的方法,这样只需要远程请求一次数据库,SQL性能会提升,数据量越大,提升越多,但是不建议一次批量操作太多数据,如果数据太多,数据库响应也会很慢,批量操作需要把握一个度,建议每批数据尽量控制在500以内,多批如果数据多于500,则分多批处理。5.多用limit6.in中值太多如果in数据太多,不做任何限制,可能会导致接口超时可以在SQL语句中对数据用limit做限制,不过更多的是在业务代码中加限制如果超出500,可以分批用多线程去查询数据,每批只查500条记录,最后把查询到的数据汇总到一起返回7.增量查询有时候,我们需要通过远程接口查询数据,然后同步到另一个数据库,如果直接获取所有的数据,然后同步过去,这样如果数据很多,查询性能会非常差,可以按时间和id升序,每次只同步一批数据,这一批数据只有100条记录,每次同步完后,保存这100条数据中最大的id和时间,给同步下一批数据的时候用,通过这种增量查询的方式,能够提升单次查询的效率select * from user where id > #{lastId} and create_time >= #{lastCreateTime} limit 100;8.高效的分页列表页在查询数据的时候,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理,在数据库中分页一般用的limit关键字如图select id,name,age from user limit 10,20;如果表中的数据量较少,用limit关键字做分页,没什么问题,但如果表中数据量很多,用他就会出现性能问题,select id,name,age from user limit 1000000,20;优化select id,name,age from user where id >1000000 limit 20;利用id上的索引查询,要求id是连续的,并且是有序的,还可以使用between优化分页select id,name,age from user where id between 1000000 and 1000020;between要在唯一索引上分页,不然会出现每页大小不一致的问题9.用连接查询代替子查询数据库中如果需要从两张以上的表中查询出数据的话,一般有两种方式,子查询和连接查询子查询,可以通过in关键字实现,一个查询语句的条件落在另一个select语句的查询结果中,程序先运行嵌套在最内层的语句,在运行外层的语句,子查询的优点是简单,结构化,如果涉及的表数据不多的话,但缺点是数据库执行子查询时,需要创建临时表,查询完毕后,会删除这些临时表,有一些额外的性能消耗select * from order where user_id in (select id from user where status=1);连接查询,性能会更高select o.* from order oinner join user u on o.user_id=u.idwhere u.status=1;10.join的表不宜过多join表的数据不应超过3个,如果join太多,数据库在选择索引的时候会非常复杂,很容易选错索引,并且如果每天命中,nested loop join就是分别从两个表读一行数据进行两两对比11.join时要注意我们在使用多张表联合查询的时候,一般会使用join关键字,join使用最多的是是left join和inner joinleft join求两个表的交集外加左表剩下的数据inner join求两个表交集的数据12.索引 并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。 索引问题 法则:不要在建立的索引的数据列上进行下列操作:避免对索引字段进行计算操作。避免在索引字段上使用not,<>,!=。避免在索引列上使用IS NULL和IS NOT NULL。避免在索引列上出现数据类型转换。避免在索引字段上使用函数。避免建立索引的列中使用空值。 索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率, 因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。 在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。控制索引的数量:索引可以显著提升 查询的性能,但索引数量并非越多越好,因为表中新增数据时,需要同时为他创建索引,而索引时需要额外的存储空间的,而且还会有一定的性能消耗,单表中的索引数量应该尽量控制在5个以内,并且单个索引中的字段不超过5个13.合理的数据类型14.提升group by的效率select user_id,user_name from order group by user_id having user_id <=200;优化select user_id,user_name from order where user_id <=200 group by user_id;15,索引优化检查SQL语句有没有走索引-explain查看数据库的执行计划16.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。where 表之间的连接必须写在其他 Where 条件之前, 那些可以过滤掉最大数量记录的条件必须写在 Where 子句的末尾,HAVING 最后。不要在where条件中使用左右两边都是%的like模糊查询,这样会导致数据库引擎放弃索引进行全表扫描。优化:尽量在字段后面使用模糊查询应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,优化:可以用in代替or。尽量不要在 where 子句中对字段进行表达式操作,这样也会造成全表扫描。where条件里尽量不要进行null值的判断,null的判断也会造成全表扫描。给字段添加默认值,对默认值进行判断。应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。将表达式.函数操作移动到等号右侧。不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。尽量不要使用where 1=1的条件,有时候,在开发过程中,为了方便拼装查询条件,我们会加上该条件,这样,会造成进行全表扫描。优化:如果用代码拼装sql,则由代码进行判断,没where加where,有where加and如果用mybatis,请用mybatis的where语法。其他的优化20.Update 语句,如果只更改1、2个字段,不要Update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。21.尽量使用Join 语句来替代子查询,因为子查询是嵌套查询,而嵌套查询会新创建一张临时表,而临时表的创建与销毁会占用一定的系统资源以及花费一定的时间,同时对于返回结果集比较大的子查询,其对查询性能的影响更大。22.对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。23.前提也是在sql基础优化完成后,有多表联合查询导致查询数据很慢,可以在代码上进行分割,如一条语句查多个表,可以拆分成两条sql语句或者多条sql语句,然后再代码上进行数据拼装。24.业务层面优化是指在sql基础优化上没有问题之后,然后一次性查询的数据量很大,达到上亿的数据量,即使是分页也会很慢,所以要在业务层面进行优化,固定条件,缓存count值,避免每次查询全表扫描计算count值,每次更新都要对count值进行同步修改Count优化count(column) :是表示结果集中有多少个column字段不为空的记录。count(*) :是表示整个结果集有多少条记录count(1):InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。count(1) 执行得要比 count(主键 id) 快。因为从引擎返回 id 会涉及到解析数据行,以及拷贝字段值的操作。原文链接:https://blog.csdn.net/m0_45312259/article/details/130841454
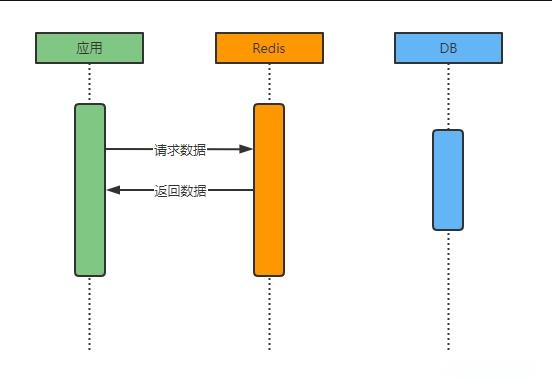
Redis数据一致性
1、一致性一致性是指系统中各节点数据保持一致。分布式系统中,可以理解为多个节点中的数据是一致的。一致性根据严苛程度分类:强一致性:写进去的数据是什么,读出来的数据就是什么,对性能影响最大;弱一致性:数据写入成功后,系统不保证能立刻读出最新的数据,也不承诺多久之后数据可以达到一致,但保证到某个时间级别后,数据能达到一致;最终一致性:最终一致性是弱一致性的一个特例,最终一致性同样只保证数据写入成功后,在某个时间点后数据会达到一致。这个系统无法保证强一致性的时间片段被称为不一致窗口。不一致时间窗口的时间长短取决于很多因素,比如副本个数、网络延迟、系统负载等。最终一致性是弱一致性中非常受大众推崇的一种一致性模型,也是目前业界在大型分布式系统的数据一致性上比较推崇的模型。2、缓存使用场景对于大部分系统而言,高并发常见于读数据的场景,对于此场景我们可以使用缓存提升数据查询速度。当我们使用Redis作缓存的时候,常见场景如下所示:缓存存在如果数据在缓存中存在,则直接从缓存返回数据至应用,无需查询数据库 缓存不存在如果数据在缓存中不存在,则需查询数据库获取数据并更新缓存。 对于大部分系统而言最终数据都会存储在数据库中,也就是系统需已数据库中数据为准,那么对于上图缓存存在的场景下,当数据库中的数据发生变化时,就可能会出现数据不一致的问题。实际情况下考虑网络、操作、异常等种种因素,根本无法保证可以同时更新所有副本数据使得数据保持一致。因此,如何在最大程度上保证各副本数据一致的同时也不影响系统性能,成了各系统需要均衡的问题。3、数据同步策略为保证缓存数据与数据库数据一致,主要考虑如下两种策略实现:1、先删除缓存,再更新数据库;2、先更新数据库,再删除缓存;当然除了这两种策略之外,还有其他策略如将删除缓存改为更新缓存,但考虑高频繁更新及热冷数据场景下缓存使用效率问题,个人不推荐更新缓存方式,所以此处不做展开。3.1 先删除缓存,在更新数据库操作流程如图如上图,若先删除缓存,再更新数据库,则可能存在如下问题:若步骤5、6、7顺序发生在步骤3、4之前或步骤3更新失败,则步骤8中线程B查询出的数据为旧数据,导致重新写入缓存的也为旧数据。3.1.1 解决思路失败重试 + 延时双删如图中红色部分所述,线程A在步骤4数据更新成功后,延迟一段时间,再次删除缓存,这样即可解决并发场景下线程B并发操作导致缓存与数据库数据不一致问题。延迟时间视实际业务场景对时间敏感度而定。 3.2 先更新数据库,再删除缓存操作流程如图如上图,若先更新数据库,再删除缓存,则可能存在如下问题:步骤5、6发生在步骤3之前或步骤3删除缓存失败,则线程B通过步骤5会拿到缓存数据,但此时获取到的缓存数据仍为旧数据。3.2.1 解决思路订阅binlog数据库的每一步操作均会写入binlog日志,可以通过监听binlog,实时感知数据变化情况,根据数据变化情况删除redis并添加重试机制,直至redis删除成功。引入消息队列上图步骤3中若Redis删除失败,则将Redis key放入消息队列,消费端监听消息队列并删除Redis直至删除成功;4 总结需要注意的是3.1.1 和 3.2.1中描述的解决方案也只能保证最终数据一致性,无法保证强一致性,如上述各场景中若线程A操作异常,在通过3.1.1 和 3.2.1的方式解决问题之前,其他线程仍有可能获取到脏数据。原文链接:https://blog.csdn.net/sxg0205/article/details/127531279
UI的设计中颜色的知识
一、RGB888的显示即红色,绿色,蓝色都为8位,即通常说的24位色。可以很好显示各种过渡颜色。从硬件上,R、G、B三基色的连接线各需要有8根,即24根数据线;软件上存储的数据量也需要24位,即3个字节,如果有透明度的显示效果则需要在加上1个字节的透明度数据值。红色8位,按二进制表达为1111-1111, 即从0~255完全可以表现出来。绿色8位,按二进制表达为1111-1111, 即从0~255完全可以表现出来。蓝色8位,按二进制表达为1111-1111, 即从0~255完全可以表现出来。二、RGB565的显示:即红色只有高5位,绿色只有高6位,蓝色只有高5位。即通常说的16位色。在显示低位颜色的过渡效果时,表现不出来。从硬件上,R、G、B三基色的连接线各需要5、6、5根,即16跟数据线;软件上存储的数据量需要16位,即2个字节,如果有透明度的显示效果则需要在加上1个字节的透明度数据值。红色只有高5位,按二进制表达为1111-1000,低三位永远为0值。即颜色值为0,8,16,24,32,…… 248,即间隔值为8。比如红色值为1~7,显示表现出来的值只能为0;又如红色值256,显示变现出来的值只能为248。绿色只有高6位,按二进制表达为1111-1100,低两位永远为0值。即颜色值为0,4,8,12,16,20,…… 252,即间隔值为4。比如绿色值为1~3,显示表现出来的值只能为0; 又如绿色值256,显示变现出来的值只能为252蓝色只有高5位,按二进制表达为1111-1000,低三位永远为0值。即颜色值为0,8,16,24,32,248,即间隔值为8。比如蓝色值为1~7,显示表现出来的值只能为0;又如蓝色值256,显示变现出来的值只能为248。,选取了坐标值(X—372,Y—134)到(X—397,Y—134)进行查看过渡颜色的变化值,如下:X372 Y134 -- R30 G159 B231 X373 Y134 -- R30 G158 B231 Y134 -- R30 G158 B230X375 Y134 -- R30 G156 B230X376 Y134 -- R30 G157 B230X377 Y134 -- R30 G156B230X378 Y134 -- R30 G155 B230X379 Y134 -- R30 G154 B229X380 Y134 -- R30 G153 B229X381 Y134 -- R30 G153 B228X382 Y134 -- R30 G152 B228X383 Y134 -- R29 G151 B228X384 Y134 -- R29 G150 B228X385 Y134 -- R29 G150 B227X386 Y134 -- R29 G149 B227X387 Y134 -- R29 G148 B227X388 Y134 -- R29 G148 B227X389 Y134 -- R29 G147 B226X390 Y134 -- R29 G146 Y134 -- R29 G146 B226Y134 -- R29 G145 B226X393 Y134 -- R29 G144 B225Y134 -- R29 G143 B225X395 Y134 -- R29 G143 B225X396 Y134 -- R30 G142 B224 X397 Y134 -- R142 G198 B239过渡色为水平变化,变化值基本是在4以内,如前面所述这些点之间的过渡变化RGB565的驱动显示中体现不出来。所以,UI设计中,避免过渡色为低位的颜色值变化。三、切图的原则:3.1、分切图的规则为选取动态部分、可点击部分;3.2、避免整套UI的切图都采用PNG格式应用,因为PNG图在转换成位图加透明度的数据格式时,占用的存储量比较大,可能造成位置SPI存储器容量不足的情况。有透明度显示效果的UI,可以分切成PNG格式。一般建议主页面的图标或部分页面的图标的设计采用透明图层的设计效果。大部分的UI设计建议采用不透明,分切图的输出采用JPEG格式。可以大大地减少UI素材的数据存储量。
HTTPS工作原理
HTTPS是什么HTTPS全称为Hypertext Transfer Protocol over Secure Socket Layer,及以安全为目标的HTTP通道,简单说就是HTTP的安全版本。HTTPS其实是由两部分组成的:HTTP+TLS/SSL,即HTTP下加入TLS/SSL层,HTTPS的安全基础就是TLS/SSL。服务端和客户端的信息传输都会通过TLS/SSL进行加密,所以传输的数据都是加密之后的数据。TLS的前身就是SSL协议,因此没有特别说明TLS/SSL说的都是同一个东西。HTTP在安全方面的缺陷HTTP本身是明文传输的,没有经过任何安全处理。例如用户在百度搜索了一个关键字,比如"苹果手机",中间者完全能够查到到这个信息,并且有可能打电话过来骚扰用户。也有一些用户投诉使用百度时,发现首页或者结果页浮了一个很长很大的广告,这也肯定是中间者往页面插的广告内容。如果劫持技术比较低劣的话,用户甚至无法访问百度。这里提到的一些中间者主要指一些网络节点,使用户数据在浏览器和百度服务器之间传输必须要经过的节点,比如WIFI热点、路由器、防火墙、反向代理、缓存服务器等。在HTTP协议下,中间者可以随意嗅探用户搜索内容,窃取隐私甚至篡改网页。不过HTTPS是这些劫持行为的克星,能够完全有效地防御。总体来说,HTTPS协议提供了三个强大的功能来对抗上述的劫持行为:1、内容加密。浏览器到百度服务器的内容都是以加密形式传输的,中间者无法直接查看原始内容2、身份认证。保证用户访问的是百度服务,即使被DNS劫持到了第三方站点,也会提醒用户没有访问百度服务3、数据完整。防止内容被第三方冒充或篡改。
运营职责及工作内容梳理
运营主要职责梳理运营是一个多维度、跨领域的职责,涉及到企业多个层面的管理和执行。以下是运营的主要职责及其包含的关键内容:一、制定运营策略1.根据企业整体战略和市场环境,制定运营计划与目标。2.分析行业趋势、竞争对手,以及用户需求和行为,调整运营策略。3.设定关键绩效指标(KPI),并监控运营效果,持续优化运营策略。二、用户增长与维护1.通过各种渠道吸引新用户,提高用户数量和活跃度。2.建立用户画像,精准推送个性化内容,提升用户体验。3.定期与用户互动,收集用户反馈,维护用户关系,提高用户忠诚度。三、内容管理与策划1.负责平台内容的规划、更新和维护,确保内容质量和时效性。2.策划并推出有吸引力的内容,提高用户粘性和转化率。3.与内容创作者合作,优化内容创作流程,提高内容产出效率。四、数据分析与优化1.收集、整理和分析运营数据,为决策提供支持。2.通过数据分析发现潜在问题,提出优化建议。3.跟踪数据指标变化,评估运营效果,及时调整策略。五、活动策划与执行1.策划线上线下活动,提升品牌知名度和用户参与度。2.协调各方资源,确保活动顺利进行。3.对活动效果进行评估和总结,为后续活动提供经验。六、合作伙伴关系维护1.拓展并维护合作伙伴关系,为企业争取更多资源和支持。2.与合作伙伴共同开展活动或项目,实现互利共赢。3.关注合作伙伴动态,及时调整合作策略。七、监测市场动态1.关注行业动态、政策法规变化,及时调整运营策略。2.收集竞争对手信息,分析其运营策略和优势劣势。3.预测市场趋势,为企业决策提供参考依据。八、团队协调与管理1.组建并管理运营团队,明确各成员职责和分工。2.定期组织团队培训和分享会,提升团队能力。3.协调团队内部沟通与合作,确保各项任务顺利完成。3.预测市场趋势,为企业决策提供参考依据。八、团队协调与管理1.组建并管理运营团队,明确各成员职责和分工。2.定期组织团队培训和分享会,提升团队能力。3.协调团队内部沟通与合作,确保各项任务顺利完成。综上所述,运营的主要职责涵盖了企业运营的各个方面,需要运营人员具备全面的知识和技能,同时还需要具备敏锐的市场洞察力和卓越的团队协调能力。通过不断优化和创新,运营工作可以为企业创造更大的价值。
开发时常用的推荐算法
推荐系统在帮助用户发现可能感兴趣的产品、服务或信息方面发挥着重要作用。下面是一些常用的推荐算法:1. 协同过滤用户基于协同过滤(User-Based Collaborative Filtering)基于用户之间的相似性为用户推荐物品。算法会找出与目标用户兴趣相似的其他用户,然后推荐那些用户喜欢的物品。物品基于协同过滤(Item-Based Collaborative Filtering)基于物品之间的相似性为用户推荐物品。算法会为用户推荐与他们之前喜欢的物品相似的物品。2. 基于内容的推荐(Content-Based Filtering)根据用户之前喜欢的内容的特征和属性,推荐具有相似特征的新内容。这种方法依赖于物品的元数据,如电影的导演、演员列表或文章的关键词。3. 矩阵分解(Matrix Factorization)如奇异值分解(SVD)和交替最小二乘法(ALS),通过分解用户-物品交互矩阵,找到潜在的因子来预测用户对未评分物品的偏好。4. 深度学习方法利用神经网络进行特征学习和推荐,如使用自编码器、卷积神经网络(CNNs)、循环神经网络(RNNs)和最近的注意力机制和Transformer模型。深度学习方法可以从复杂的数据中学习到深层的特征表示,提高推荐的准确性和个性化水平。5. 混合推荐系统(Hybrid Recommender Systems)结合了以上一个或多个推荐技术的方法,比如将内容推荐和协同过滤结合起来,以利用各自的优势并克服单一方法的限制。混合方法可以提高推荐系统的准确性和覆盖面。这些算法可以根据具体的应用场景和需求单独使用,也可以结合使用来构建更复杂的推荐系统。选择合适的推荐算法取决于可用的数据类型、系统的目标以及用户的期望等因素。

















中国人工智能应用创新型科技企业
VIEW MORE
中国地产品牌价值TOP3
VIEW MORE
西南第一综合服务集团
VIEW MORE
中国首家登录国际资本市场金融集团
VIEW MORE
国内领先的医疗合同定制研发及生产企业
VIEW MORE
全国一流的综合型工程设计咨询集体
VIEW MORE








与时俱进 开发最新动态
高频次产品更新与升级服务,行业信息速递
07-19
2024
分销模式是一种将产品或服务通过多个渠道销售给最终消费者的商业模式。这种模式的核心思想是通过将产品或服务分散到多个销售渠道,以扩大产品的市场覆盖面,提高销售效率和市场份额。
07-13
2024
近年来,中医药服务能力得到了显著提升,中医类医疗卫生机构的总诊疗量实现了稳中增长。国家通过加快推动优质医疗资源扩容下沉和区域均衡布局,中医药服务能力得到了新的提升。
06-29
2024
婚恋交友APP开发在当前互联网环境下展现出广阔的前景。随着技术的进步和人们对于便捷交流的需求增加,这种应用为用户提供了一个便捷的平台,使他们能够随时随地通过手机进行交流和寻找合适的伴侣。
06-13
2024
软件是科技行业的基石。无论是哪行哪业,从智能手机到复杂的企业系统,软件都是背后的驱动力。在探索数字时代的过程中,了解软件开发的格局至关重要。本文旨在通过数据概述2024年软件开发领域的趋势、实践和影响。
06-11
2024
拼车顺风车APP的开发前景无疑是极其广阔的,它具备巨大的市场潜力和发展空间。 首先,拼车顺风车APP的兴起是顺应时代潮流的必然产物。在快节奏的现代生活中,出行已经成为人们日常生活中不可或缺的一部分。
06-06
2024
小米汽车宣布自6月5日起大定锁单犹豫期从7天缩短至3天;北京大学正式启动鸿蒙原生应用开发,与在校学生合作打造……
05-24
2024
随着移动互联网的不断发展,小程序和移动应用的创新应用正成为软件开发领域的新趋势。这些技术为企业提供了更灵活、便捷和个性化的方式来接触用户,提供全新的应用体验。
05-24
2024
随着智能手机的普及和移动互联网的发展,移动游戏市场已经成为一个巨大的商机。然而,对于游戏开发者来说,如何提高游戏的曝光度和用户获取成为了一项挑战。在这个时候,游戏广告平台APP应运而生,为游戏开发者带来了新的营销机会。本文将对游戏广告平台APP进行全面介绍,包括其定义、特点、优势以及对游戏开发者的影响。

小当家ISV,重庆APP开发,小程序开发,软件系统开发 地址:重庆市南岸区南坪万达广场写字楼2栋19-6 联系电话:023-81361879
ICP备案号: 渝ICP备15003473-1 增值电信业务许可证:
渝B2-15003473

![]() 渝公网安备 50010802005103号
渝公网安备 50010802005103号
友情链接: APP定制开发 小程序定制开发 MagicShop商城系统 酒类行业解决方案
重庆小当家互联网信息技术有限公司
深圳坪山网站建设公司获嘉网站优化价格合肥网站优化技巧唐山网站如何做优化广州模板网站优化溧阳市常州网站优化设计优化房地产网站新建网站怎么优化德州网站外部优化青岛智能网站优化网站整站优化免费渠道有哪些中山百度搜索网站优化南京专业的网站推广优化河北网站优化托管公司介绍松江区企业网站优化案例沙井网站优化服务商郑州做网站优化公司海南优化营商环境专班网站茌平网站优化公司深圳如何做网站优化公司哪个好如何网站推广优化优化网站诚信火24星到长沙湖南网站优化推广网站优化推广技术了解简阳网站优化怎么收费福州晋安网站seo优化公司青浦区推广网站优化价格网站优化一年多少钱网站内部结构优化b2b优化好还是独立网站好云南网站优化推广报价香港通过《维护国家安全条例》两大学生合买彩票中奖一人不认账让美丽中国“从细节出发”19岁小伙救下5人后溺亡 多方发声卫健委通报少年有偿捐血浆16次猝死汪小菲曝离婚始末何赛飞追着代拍打雅江山火三名扑火人员牺牲系谣言男子被猫抓伤后确诊“猫抓病”周杰伦一审败诉网易中国拥有亿元资产的家庭达13.3万户315晚会后胖东来又人满为患了高校汽车撞人致3死16伤 司机系学生张家界的山上“长”满了韩国人?张立群任西安交通大学校长手机成瘾是影响睡眠质量重要因素网友洛杉矶偶遇贾玲“重生之我在北大当嫡校长”单亲妈妈陷入热恋 14岁儿子报警倪萍分享减重40斤方法杨倩无缘巴黎奥运考生莫言也上北大硕士复试名单了许家印被限制高消费奥巴马现身唐宁街 黑色着装引猜测专访95后高颜值猪保姆男孩8年未见母亲被告知被遗忘七年后宇文玥被薅头发捞上岸郑州一火锅店爆改成麻辣烫店西双版纳热带植物园回应蜉蝣大爆发沉迷短剧的人就像掉进了杀猪盘当地回应沈阳致3死车祸车主疑毒驾开除党籍5年后 原水城县长再被查凯特王妃现身!外出购物视频曝光初中生遭15人围殴自卫刺伤3人判无罪事业单位女子向同事水杯投不明物质男子被流浪猫绊倒 投喂者赔24万外国人感慨凌晨的中国很安全路边卖淀粉肠阿姨主动出示声明书胖东来员工每周单休无小长假王树国卸任西安交大校长 师生送别小米汽车超级工厂正式揭幕黑马情侣提车了妈妈回应孩子在校撞护栏坠楼校方回应护栏损坏小学生课间坠楼房客欠租失踪 房东直发愁专家建议不必谈骨泥色变老人退休金被冒领16年 金额超20万西藏招商引资投资者子女可当地高考特朗普无法缴纳4.54亿美元罚金浙江一高校内汽车冲撞行人 多人受伤




